DashAttention: Differentiable and Adaptive Sparse Hierarchical Attention
Current hierarchical attention methods, such as NSA and InfLLMv2, select the top-k relevant key-value (KV) blocks based on coarse …

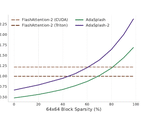
AdaSplash-2: Faster Differentiable Sparse Attention
Sparse attention has been proposed as a way to alleviate the quadratic cost of transformers, a central bottleneck in long-context …
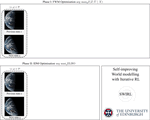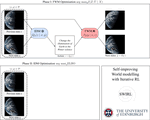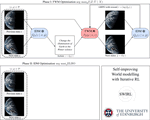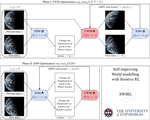
Self-Improving World Modelling with Latent Actions
Internal modelling of the world — predicting transitions between previous states X and next states Y under actions Z — is essential to …
Bolmo: Byteifying the Next Generation of Language Models
Recent advances in generative AI have been largely driven by large language models (LLMs), deep neural networks that operate over …

Fast and Expressive Multi-Token Prediction with Probabilistic Circuits
Multi-token prediction (MTP) is a prominent strategy to significantly speed up generation in large language models (LLMs), including …
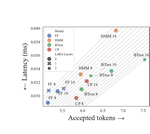
Inference-Time Hyper-Scaling with KV Cache Compression
Inference-time scaling trades efficiency for increased reasoning accuracy by generating longer or more parallel sequences. However, in …

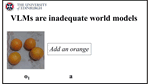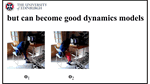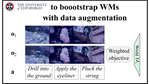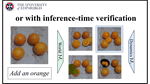
Bootstrapping Action-Grounded Visual Dynamics in Unified Vision-Language Models
Can unified vision-language models (VLMs) perform forward dynamics prediction (FDP), i.e., predicting the future state (in image form) …
The Sparse Frontier: Sparse Attention Trade-offs in Transformer LLMs
Sparse attention offers a promising strategy to extend long-context capabilities in Transformer LLMs, yet its efficiency-accuracy …

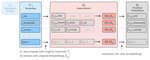
Zero-Shot Tokenizer Transfer
Language models (LMs) are bound to their tokenizer, which maps raw text to a sequence of vocabulary items (tokens). This restricts …
Dynamic Memory Compression: Retrofitting LLMs for Accelerated Inference
Transformers have emerged as the backbone of large language models (LLMs). However, generation remains inefficient due to the need to …
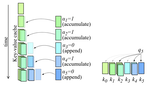
Efficient Transformers with Dynamic Token Pooling
Transformers achieve unrivalled performance in modelling language, but remain inefficient in terms of memory and time complexity. A …
