Informing Unsupervised Pretraining with External Linguistic Knowledge
Informing Unsupervised Pretraining with External Linguistic Knowledge
Abstract
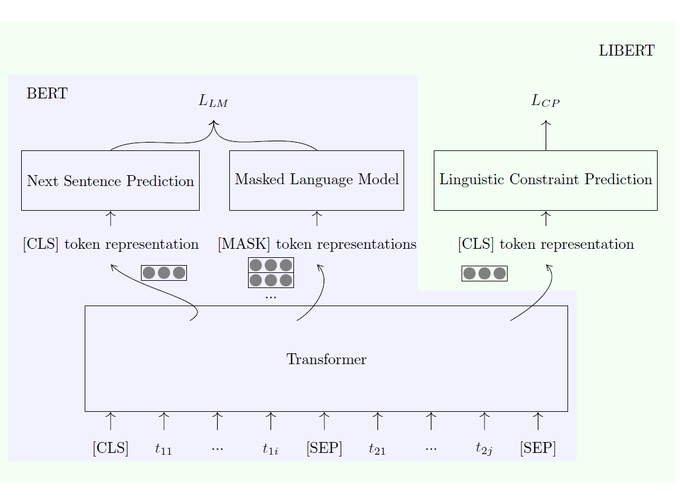
Unsupervised pretraining models have been shown to facilitate a wide range of downstream applications. These models, however, still encode only the distributional knowledge, incorporated through language modeling objectives. In this work, we complement the encoded distributional knowledge with external lexical knowledge. We generalize the recently proposed (state-of-the-art) unsupervised pretraining model BERT to a multi-task learning setting: we couple BERT’s masked language modeling and next sentence prediction objectives with the auxiliary binary word relation classification, through which we inject clean linguistic knowledge into the model. Our initial experiments suggest that our “linguistically-informed” BERT (LIBERT) yields performance gains over the linguistically-blind “vanilla” BERT on several language understanding tasks.