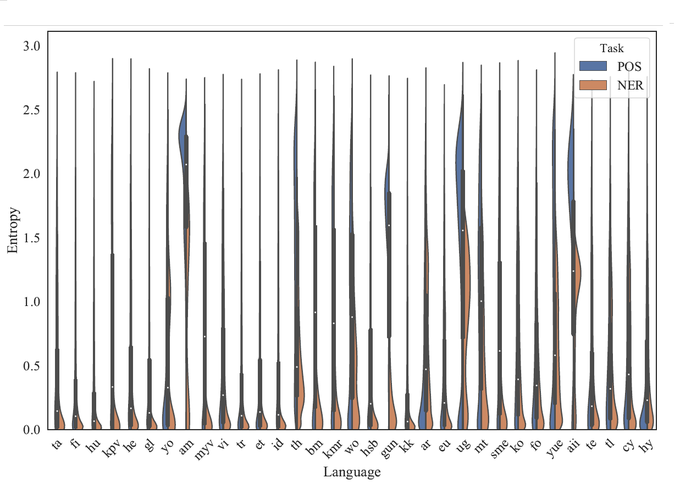
Abstract
Most combinations of NLP tasks and language varieties lack in-domain examples for supervised training because of the paucity of annotated data. How can neural models make sample-efficient generalizations from task-language combinations with available data to low-resource ones? In this work, we propose a Bayesian generative model for the space of neural parameters. We assume that this space can be factorized into latent variables for each language and each task. We infer the posteriors over such latent variables based on data from seen task-language combinations through variational inference. This enables zero-shot classification on unseen combinations at prediction time. For instance, given training data for named entity recognition (NER) in Vietnamese and for part-of-speech (POS) tagging in Wolof, our model can perform accurate predictions for NER in Wolof. In particular, we experiment with a typologically diverse sample of 33 languages from 4 continents and 11 families, and show that our model yields comparable or better results than state-of-the-art, zero-shot cross-lingual transfer methods; it increases performance by 4.49 points for POS tagging and 7.73 points for NER on average compared to the strongest baseline.