Adaptive Tokenization and Memory in Foundation Models
for Efficient and Long-Horizon AI (AToM ⚛︎)
The recent revolution in generative AI has been driven by the rapid growth in training and inference compute for Foundation Models (FMs). This scaling, however, brings unintended consequences, including high energy demand and associated carbon emissions. My research sets out to reverse this trend by targeting a fundamental inefficiency in dominant FM architectures such as Transformers. Currently, these map data into sequences of internal representations, whose length bottlenecks both prompt processing (compute-bound by typically quadratic attention) and output generation (memory-bandwidth bound by key–value cache reads). Yet this length is largely determined upfront by input segmentation (tokenisation) and typically remains fixed across layers; during decoding, it also accumulates unchanged in the key–value cache.
I have prototyped a new class of FM architectures that learn, end-to-end, to compress sequences of internal representations, effectively redefining the model’s “atomic units” for processing and memorising information. To accelerate adoption, I have repurposed existing state-of-the-art open-weight FMs (such as Qwen 3 in collaboration with NVIDIA and OLMo in collaboration with AI2) into adaptive variants and released them publicly.
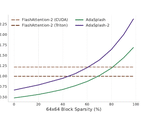
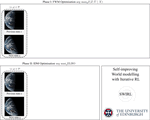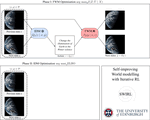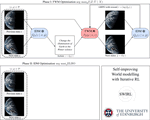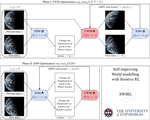
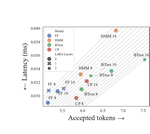
This leads not only to substantial gains in efficiency (with 8× speedups without accuracy degradation) but also to the emergence of new capabilities: adaptive FMs can operate over broader effective horizons, as they can perceive longer inputs and generate longer outputs under a fixed budget. This enables (1) lifelong learning via a permanent, sub-linearly growing memory, (2) inference-time hyper-scaling for reasoning-intensive tasks (maths, science, coding), and (3) enhanced world modelling for multimodal planning and simulation. Adaptive FMs thus open a path towards greener, more capable generative AI.