Multilingual Language Modelling (RASA AI Meetup)
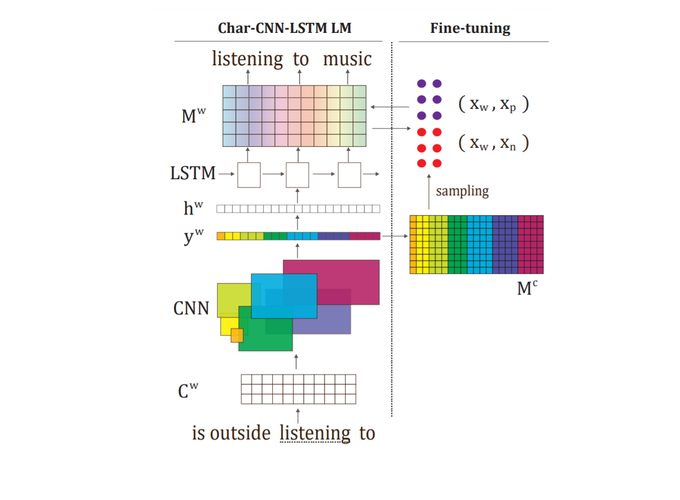 CNN+LSTM+Attract-Preserve
CNN+LSTM+Attract-Preserve
Multilingual Language Modelling (RASA AI Meetup)
Abstract
A key challenge in cross-lingual NLP is developing general language-independent architectures that are equally applicable to any language. However, this ambition is largely hampered by the variation in structural and semantic properties, i.e. the typological profiles of the world’s languages. In this work, we analyse the implications of this variation on the language modeling (LM) task. We present a large-scale study of state-of-the art n-gram based and neural language models on 50 typologically diverse languages covering a wide variety of morphological systems. Operating in the full vocabulary LM setup focused on word-level prediction, we demonstrate that a coarse typology of morphological systems is predictive of absolute LM performance. Moreover, fine-grained typological features such as exponence, flexivity, fusion, and inflectional synthesis are borne out to be responsible for the proliferation of low-frequency phenomena which are organically difficult to model by statistical architectures, or for the meaning ambiguity of character n-grams. Our study strongly suggests that these features have to be taken into consideration during the construction of next-level language-agnostic LM architectures, capable of handling morphologically complex languages such as Tamil or Korean.